

How seamless is running a LLM-generated code?
These days, everyone and their grandparents are talking about AI taking over human jobs. You cannot scroll through social media without seeing some CEO of a global conglomerate talking about how by 202x traditional programming jobs will be eaten up by AI agents. A new concept called Vibe Coding has emerged, where one relies purely on LLM-generated code to develop something grand. We thought of putting things to test and see it for ourselves how big this threat really is.
Our simple test case
Write a Python script to traverse all pages of a website and find issues like missing images, 404 errors (not found) and circular redirects (Page A → Page B → Page A). It should be easy to run. All we need to do is enter the website URL.
LLM Used:
OpenAI GPT-4o
Exact Prompt:
Write a Python script to traverse all pages of a website and find issues like missing images, 404 errors and circular redirects. It should be easy to run. All I need to do is enter the website URL.

The LLM Output
Best viewed on Desktop
import sys
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
from collections import deque
visited = set()
redirects_seen = set()
broken_links = []
missing_images = []
circular_redirects = []
def is_internal(link, domain):
return urlparse(link).netloc in ["", domain]
def get_page(session, url):
try:
response = session.get(url, timeout=10, allow_redirects=True)
final_url = response.url
if response.status_code == 404:
broken_links.append((url, response.status_code))
elif final_url != url:
redirect_pair = (url, final_url)
if redirect_pair in redirects_seen:
circular_redirects.append(redirect_pair)
else:
redirects_seen.add(redirect_pair)
return response
except Exception as e:
broken_links.append((url, str(e)))
return None
def crawl(start_url):
domain = urlparse(start_url).netloc
queue = deque([start_url])
session = requests.Session()
while queue:
current_url = queue.popleft()
if current_url in visited:
continue
visited.add(current_url)
print(f"Visiting: {current_url}")
response = get_page(session, current_url)
if response is None or not response.headers.get("content-type", "").startswith("text/html"):
continue
soup = BeautifulSoup(response.text, "html.parser")
# Check for missing images
for img in soup.find_all("img"):
src = img.get("src")
if not src:
continue
img_url = urljoin(current_url, src)
try:
img_response = session.get(img_url, timeout=10)
if img_response.status_code == 404:
missing_images.append((img_url, current_url))
except Exception as e:
missing_images.append((img_url, f"{current_url} (error: {e})"))
# Add internal links to queue
for link_tag in soup.find_all("a"):
href = link_tag.get("href")
if not href:
continue
next_url = urljoin(current_url, href)
if is_internal(next_url, domain) and next_url not in visited:
queue.append(next_url)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python site_checker.py https://example.com")
sys.exit(1)
start_url = sys.argv[1]
crawl(start_url)
print("\n--- Report ---")
print(f"Pages visited: {len(visited)}")
print("\nBroken links (404 or errors):")
for link, error in broken_links:
print(f"- {link} ({error})")
print("\nMissing images:")
for img_url, page in missing_images:
print(f"- {img_url} (found in {page})")
print("\nCircular redirects:")
for original, final in circular_redirects:
print(f"- {original} -> {final}")
Dependencies
Install required libraries:
pip install requests beautifulsoup4
Run it:
python site_checker.py https://yourwebsite.com
Initial Reaction to the LLM-generated code
- We didn’t specify to the LLM what level of Python proficiency we have. Therefore, the output is pretty good.
- It clearly highlighted two libraries we need to install: request and beautifulsoup4.
- Correct use of data structures.
- The code also looks clean, with “pythonic” naming conventions and some inline comments.
So far so good!
Getting the setup done
Here are the steps we followed:
- Pasted this code in our text editor (Visual Studio Code)
- Installed the dependencies (requests and beautifulsoup4) using conda (which is a more modern way of managing dependencies)
- Selected the correct Python interpreter (or conda environment)
- Reloaded the window
Running the LLM-generated code ... as-is
python site_checker.py https://mantrax.io
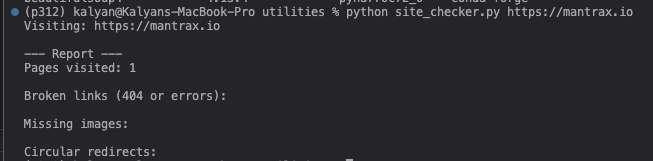
Nothing!
Listen to the vibes and provide this feedback to the LLM
Trying out the new LLM-generated code ... Take 2
Best viewed on Desktop
import sys
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse, urldefrag
from collections import deque
visited = set()
redirects_seen = set()
broken_links = []
missing_images = []
circular_redirects = []
def is_internal(url, domain):
parsed = urlparse(url)
return parsed.netloc == "" or parsed.netloc == domain
def clean_url(url):
# Strip fragments like #section
return urldefrag(url)[0].rstrip("/")
def get_page(session, url):
try:
response = session.get(url, timeout=10, allow_redirects=True)
final_url = response.url
if response.status_code == 404:
broken_links.append((url, response.status_code))
elif final_url != url:
redirect_pair = (url, final_url)
if redirect_pair in redirects_seen:
circular_redirects.append(redirect_pair)
else:
redirects_seen.add(redirect_pair)
return response
except Exception as e:
broken_links.append((url, str(e)))
return None
def crawl(start_url):
domain = urlparse(start_url).netloc
queue = deque([clean_url(start_url)])
session = requests.Session()
while queue:
current_url = queue.popleft()
if current_url in visited:
continue
visited.add(current_url)
print(f"Visiting: {current_url}")
response = get_page(session, current_url)
if not response:
continue
content_type = response.headers.get("content-type", "")
if not content_type.startswith("text/html"):
continue
soup = BeautifulSoup(response.text, "html.parser")
# Get base href if exists
base_tag = soup.find("base")
base_url = urljoin(current_url, base_tag["href"]) if base_tag and base_tag.get("href") else current_url
# Check images
for img in soup.find_all("img"):
src = img.get("src")
if not src:
continue
img_url = urljoin(base_url, src)
try:
img_response = session.get(img_url, timeout=10)
if img_response.status_code == 404:
missing_images.append((img_url, current_url))
except Exception as e:
missing_images.append((img_url, f"{current_url} (error: {e})"))
# Find and queue internal links
for tag in soup.find_all("a", href=True):
href = tag["href"]
if href.startswith(("mailto:", "javascript:", "#")):
continue
next_url = urljoin(base_url, href)
next_url = clean_url(next_url)
if is_internal(next_url, domain) and next_url not in visited:
queue.append(next_url)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python site_checker.py https://example.com")
sys.exit(1)
start_url = sys.argv[1]
crawl(start_url)
print("\n--- Report ---")
print(f"Pages visited: {len(visited)}")
print("\nBroken links (404 or errors):")
for link, error in broken_links:
print(f"- {link} ({error})")
print("\nMissing images:")
for img_url, page in missing_images:
print(f"- {img_url} (found in {page})")
print("\nCircular redirects:")
for original, final in circular_redirects:
print(f"- {original} -> {final}")
Output from Take 2
Still nothing!
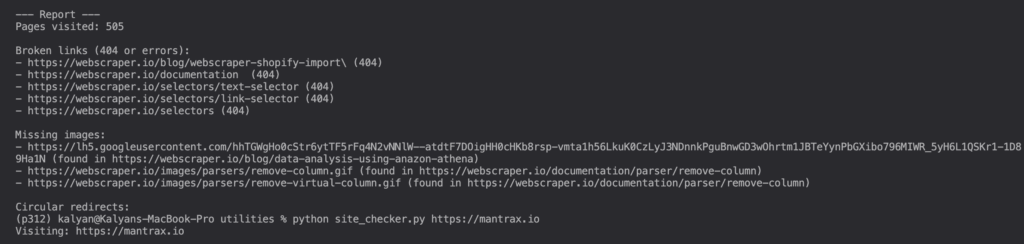
Here is the shocker! The code actually works
If you truly give in to Vibe Coding, that is, you don’t hone your skills or rely too much on AI tools to get through your tasks, a detrimental cognitive offload will happen, which we believe could hurt your critical thinking skills. That’s the point we made in an earlier post on Vibe Coding. However, if you had put on your critical thinking hat, you’d try this code on a site that’s out there for testing web scraping. One such site is https://webscraper.io/test-sites/e-commerce/allinone. We ran the site checking script using this URL and it worked!!
Conclusion on running LLM-generated code
This post was not created to bash Vibe Coding or any similar concept. The point we are trying to make is that conventional wisdom and technical acumen are not optional when it comes to building great products. LLM-generated code can improve your productivity 2x, 3x, or perhaps even more, but failing to realize basic issues (for example, maybe a site has anti-scraping measures to prevent abuse) can lead to bigger problems which might offset the productivity gains. And let’s get real. This is a simple use case which worked (albeit, with human intervention). But things may not always have a happy ending. Real-life systems are rarely this simple. Without good knowledge of systems design principles, domain knowledge and coding standards, one cannot build a good product. At least not yet!
Photo (of the cat) by John Moeses Bauan on Unsplash





